서론
온라인 서점을 주제로 프로젝트를 진행하다가, 검색 기능의 성능을 향상시키고 다양한 기능을 추가하고 싶어 찾아보다가 elasticsearch 라는 기술을 알게 되었다
우리 서비스는 MySQL DB를 사용하고 있으며, 기존 LIKE 쿼리를 사용한 검색을 사용하고 있었는데 이는 제약사항이 너무나 많고 정확하게 입력하지 않으면 검색 결과가 나오지 않는 문제가 존재했다
따라서 ELK (Elasticsearch, Logstash, Kibana) 를 도입하여 기존 DB의 데이터를 elasticsearch index에 필요한 정보만 저장하고 이를 활용하여 검색 성능 및 사용자 경험 향상에 도움을 주고자 한다
환경
OS : Ubuntu Server 20.04 LTS
CPU : 4vCPU
RAM : 8GB
SSD : 20GB
서버의 환경이고 NHN Cloud의 Instance 를 사용하였다
설치할 버전
elasticsearch, logstash, kibana : 7.16.3
mysql-connector-java : 8.0.20
해당 무작정 실행하기 에서는 Docker Compose 를 사용하지 않고, 각각의 어플리케이션을 설치 및 세팅하여 연동됨을 확인하는 것을 목표로 한다
mysql-connector-java의 경우에는 Ubuntu 버전에 따라 다를 수 있으므로 참고하여 진행하면 된다
Docker
1-1. docker 설치
❯ sudo apt-get update
❯ sudo apt-get install -y \
ca-certificates \
curl \
gnupg \
lsb-release
❯ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
❯ echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
❯ sudo apt-get update
❯ sudo apt-get install -y docker-ce docker-ce-cli containerd.io각각 공백으로 구분된 명령어를 그대로 Ubuntu 환경에서 실행하면 된다
1-2. docker 실행
❯ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES도커가 설치되었다면 아마도 도커는 실행중일 것이다
`docker ps` 명령을 입력했을 때, 다음과 같이 오류가 발생하지 않고 뜨면 정상적으로 실행된 것이다
만약 실행이 되지 않고 오류가 뜬다면, 구글에 검색해보면 많은 해결 방법이 있으니 참고하면 좋을 것이다
2-1. elasticsearch 이미지 다운로드
sudo docker pull docker.elastic.co/elasticsearch/elasticsearch:7.16.3elasticsearch 해당 버전의 이미지를 pull 해 오는 명령어 이다
$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.elastic.co/elasticsearch/elasticsearch 7.16.3 3a5e93284781 2 years ago 611MB이미지가 잘 받아졌다면, `docker images` 명령어를 통해 받아진 이미지를 볼 수 있다
2-2. elasticsearch 실행
❯ sudo docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node"
--name elasticsearch docker.elastic.co/elasticsearch/elasticsearch:7.16.3다음 명령어를 통하여 받은 이미지를 실행 시킨다
| docker (container) run [OPTIONS] IMAGE [COMMAND] [ARG...] | |
| (docker run) -d | 컨테이너를 백그라운드로 실행시키고, 컨테이너의 ID를 출력 |
| -p | 컨테이너의 포트를 지정한다 |
| -e | 환경 변수를 지정한다 |
| --name | 컨테이너의 이름을 지정한다 |
| -e "discovery.type=single-node" 는 elasticsearch 에서 싱글 노드만 사용하겠다는 설정이다 | |
45ab284ba8f73c01eab2d5c40feb678c123ebff2a50b4cb42af24857231297fb실행 후 이런 형식으로 컨테이너의 ID가 출력되면, 정상적으로 실행이 완료된 것이다
실행을 확인하기 위해서 브라우저에 `http://[서버 아이피 주소]:9200` 주소를 입력하고 들어가면
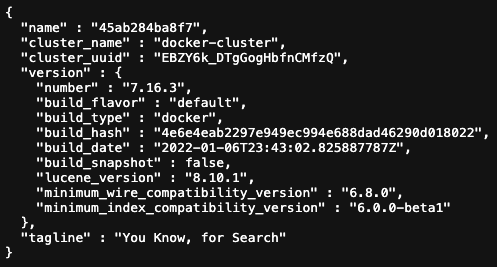
다음과 같은 JSON 형식의 응답이 보여질 것이다
이렇게 elasticsearch 가 실행 되고 있음을 확인할 수 있다
2-2. Kibana 이미지 다운로드 및 Elasticsearch 연동
sudo docker pull docker.elastic.co/kibana/kibana:7.16.3
해당 명령을 통하여, kibana 이미지도 pull 받아오는 데에 성공하였다
kibana의 실행은 현재 실행중인 elasticsearch 컨테이너와의 연결이 필요하다
❯ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
45ab284ba8f7 docker.elastic.co/elasticsearch/elasticsearch:7.16.3 "/bin/tini -- /usr/l…" 23 minutes ago Up 23 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch`docker ps` 명령을 입력하고, 현재 실행 중인 elasticsearch 의 Container ID를 복사한다
❯ docker run -d -p 5601:5601 --link 45ab284ba8f7:elasticsearch
--name kibana docker.elastic.co/kibana/kibana:7.16.3`--link` 옵션은 다른 컨테이너와 연결을 추가하는 역할을 한다
컨테이너끼리는 private ip를 기반으로 통신하는데, 컨테이너가 재시작 되면 ip가 바뀔 수도 있다
이를 해결하는 방법으로 link를 사용하고, ip가 아닌 컨테이너 이름을 기반으로 통신할 수 있기 때문이다
따라서 `--link` 옵션 뒤에 해당하는 [컨테이너 아이디]:[컨테이너 이름] 을 입력하여 두 컨테이너가 통신할 수 있도록 한다
http://[서버의 아이피 주소]:5601해당 경로로 접속했을 때, 아래 같은 페이지가 보여진다면 정상적으로 실행이 완료된 것이다
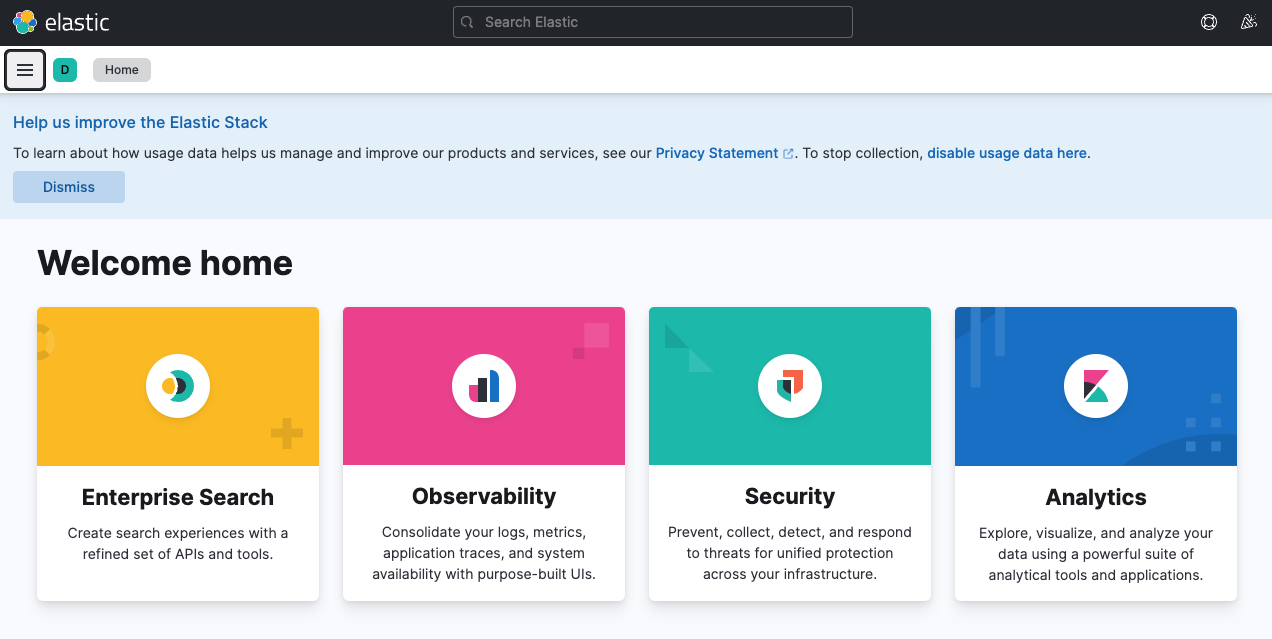
2-3. Logstash 이미지 다운로드 및 Elasticsearch 연결
sudo docker pull docker.elastic.co/logstash/logstash:7.16.3
이후 docker에 logstash 볼륨을 생성해야 한다
sudo docker volume create logstash위 명령을 통하여 docker의 볼륨을 생성해 준다
❯ sudo docker volume ls
DRIVER VOLUME NAME
local logstash`docker volume ls` 명령을 통하여 볼륨이 잘 생성되었음을 확인할 수 있다
❯ sudo docker run -p 9600:9600 -d -v logstash:/usr/share/logstash
--name logstash docker.elastic.co/logstash/logstash:7.16.3| -v [DOCKER_VOLUME]:[DIRECTORY] | 해당 docker volume을 DIRECTORY 와 연결해 준다 |
다음 명령을 통해, 방금 생성한 도커 볼륨을 디렉토리와 연결해 주는 옵션과 함께 컨테이너를 실행한다
2-4. 2번 과정 후 결과
ubuntu@ckin-test-elastic:~$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e2ecfbad956e docker.elastic.co/logstash/logstash:7.16.3 "/usr/local/bin/dock…" 48 seconds ago Up 42 seconds 5044/tcp, 0.0.0.0:9600->9600/tcp, :::9600->9600/tcp logstash
e041270c1f72 docker.elastic.co/kibana/kibana:7.16.3 "/bin/tini -- /usr/l…" 3 minutes ago Up 3 minutes 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
682e318c97c8 docker.elastic.co/elasticsearch/elasticsearch:7.16.3 "/bin/tini -- /usr/l…" 6 minutes ago Up 6 minutes 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch`docker ps` 명령어를 실행할 시 총 3개의 컨테이너가 실행중일 것이다
3. 환경 설정
먼저 나의 목적은 Logstash로 MySQL DB에 있는 데이터를 elasticsearch 에서 사용할 수 있도록 데이터를 가져오는 것이다
그러기 위해서는 먼저 Java 설치와 MySQL Connector Java 를 설정해야 한다
3-1. Java 설치
본 Java 설치는 Ubuntu 환경 기준으로 진행 하였습니다
$ sudo apt-get update
$ sudo apt-get upgrade
# install
$ sudo apt-get install openjdk-11-jdk위 명령어를 입력하여, 자바 11버전을 설치합니다
# 자바 버전 확인
$ java --version
openjdk 11.0.22 2024-01-16
OpenJDK Runtime Environment (build 11.0.22+7-post-Ubuntu-0ubuntu220.04.1)
OpenJDK 64-Bit Server VM (build 11.0.22+7-post-Ubuntu-0ubuntu220.04.1, mixed mode, sharing)
# 환경 변수 설정
$ export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64
$ export PATH=$PATH:$JAVA_HOME/bin이후 설치가 완료되면, 설치된 자바 버전을 확인하고
아래 `export`를 통하여 환경 변수를 등록해 줍니다
3-2. MySQL Connector Java 설치
sudo wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-java_8.0.20-1ubuntu20.04_all.deb다음 명령을 통하여 MySQL Connector Java를 다운로드 합니다
해당 커넥터의 기준은 Ubuntu 20.04 LTS 버전을 기준으로 합니다
혹시라도 다른 버전으로 다운로드 하고 싶으시다면, https://dev.mysql.com/downloads/connector/j/ 로 접속하여, 버전에 맞는 커넥터의 다운로드 링크를 복사하여 위 명령어를 작성하시면 됩니다
# 압축 해제
sudo dpkg -i mysql-connector-java_8.0.20-1ubuntu20.04_all.deb다운로드가 완료되었다면, 위 명령어와 함께 해당 파일의 압축을 해제합니다
$ cd /usr/share/java
$ ls
java-atk-wrapper.jar java_defaults.mk libintl.jar mysql-connector-java-8.0.20.jar위 경로 (/usr/share/java) 에 압축을 해제한 파일이 존재한다면, 여기까지는 성공입니다
# 관리자 권한 획득
sudo su
# .jar 파일 복사
mv mysql-connector-java-8.0.20.jar /var/lib/docker/volumes/logstash/_data
exit위 명령을 차례대로 수행하여, `.jar` 파일을 `/var/lib/docker/volumes/logstash/_data` 경로로 옮깁니다
# logstash 컨테이너 접근
sudo docker exec -it logstash bash
$ ls
bin config CONTRIBUTORS data Gemfile Gemfile.lock jdk lib logstash-core logstash-core-plugin-api modules mysql-connector-java-8.0.20.jar pipeline tools vendor x-packlogstash 컨테이너로 접근하면, 해당 경로에 아까 옮겼던 `mysql-connector-java` 파일을 볼 수 있습니다
이를 아래 명령어를 사용하여 해당 경로로 옮겨줍니다
$ mv mysql-connector-java-8.0.20.jar logstash-core/lib/jars/
3-3. logstash 설정
logstash.yml 파일 설정
vi config/logstash.ymlhttp.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://{엘라스틱서치 서버 주소}:9200" ]
path.data: 'jdbc:mysql://{데이터베이스 서버 주소}/{데이터베이스 명}'위 `elasticsearch.hosts` 에는 elasticsearch 서버 주소를 입력하고,
아래 path.data 에는 MySQL 서버 주소를 입력해 줍니다
logstash.conf 파일 설정
vi pipeline/logstash.conf위 설정이 조금 힘들 수도 있는데, 간단하게 몇 부분만 설정하면 MySQL을 연결할 수 있으니 천천히 하면 좋을 것 같다
`logstash.conf` 는 크게 세 가지 부분으로 나누어진다
input -> filter -> output
말 그대로 input은 입력된, 수집할 데이터에 대한 내용이고
filter는 들어온 input을 어떻게 가공할 것인지에 대한 내용이다
output은 가공한 데이터를 어떤 방식으로 내보낼 것인지에 대한 내용이다
Jdbc input plugin | Logstash Reference [8.12] | Elastic
If not provided, Plugin will look for the driver class in the Logstash Java classpath. Additionally, if the library does not appear to be being loaded correctly via this setting, placing the relevant jar(s) in the Logstash Java classpath rather than via th
www.elastic.co
Mutate filter plugin | Logstash Reference [8.12] | Elastic
Conversion insights The values are converted using Ruby semantics. Be aware that using float and float_eu converts the value to a double-precision 64-bit IEEE 754 floating point decimal number. In order to maintain precision due to the conversion, you shou
www.elastic.co
Elasticsearch output plugin | Logstash Reference [8.12] | Elastic
If you configure the plugin to use 'TLSv1.1' on any recent JVM, such as the one packaged with Logstash, the protocol is disabled by default and needs to be enabled manually by changing jdk.tls.disabledAlgorithms in the $JDK_HOME/conf/security/java.security
www.elastic.co
순서대로 input -> jdbc, filter -> mutate, output -> elastic 을 사용할 것이다
우리는 jdbc 플러그인을 사용하여 DB의 연결을 설정하고, 가져올 데이터를 선택하며
mutate 플로그인을 통하여 필드 이름 변경 및 삭제를 수행할 것이고
elasticsearch 플러그인을 통하여 이렇게 가공한 데이터를 elasticsearch의 index로 내보낼 것이다
이정로도만 알고 있다면, 충분히 수행할 수 있을 것이다
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-8.0.20.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://{database address}:3306/{database name}?serverTimezone=Asia/Seoul"
jdbc_user => "{user id}"
jdbc_password => "{user password}"
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
statement => "{Query}"
schedule => "/5 * * * * *"
last_run_metadata_path => "/usr/share/logstash/.logstash_jdbc_last_run"
}
}
filter {
mutate {
// 기준이 되는(PK같은) 필드를 아래에 작성하면 된다 indices의 번호가 될 것이다
// 이는 동일하게 설정해 주는 것이 좋다
copy => {"book_id" => "[@metadata][book_id]"}
remove_field => ["@version", "unix_ts_in_secs"]
}
}
output {
stdout {
}
elasticsearch {
hosts => "{elasticsearch server address}:9200"
index => "books"
document_id => "%{[@metadata][book_id]}"
}
}다음과 같이 작성해 주었다
몇가지 주의할 내용은 특정 커넥터 버전과 MySQL을 사용 시 아래와 같은 오류가 발생하는 경우가 존재하는데
The server time zone value 'KST' is unrecognized or represents more than one time zone.
이는 데이터베이스 주소 뒤에 `?serverTimezone=Asia/Seoul` 를 붙여서 해결할 수 있다
Logstash "The server time zone value 'KST' is unrecognized or represents more than one time zone." 오류 · Issue #86 · nhnaca
🚨 어떤 버그인가요? "The server time zone value 'KST' is unrecognized or represents more than one time zone." 라는 오류 메시지와 함께 Logstash가 정상적으로 실행되지 않는 오류 💥 어떤 상황에서 발생한 버그인가
github.com
SELECT b.book_id, b.book_title as title, b.book_publisher as publisher, b.book_regular_price as regular_price, b.book_sale_price as sale_price, b.book_discount_rate as discount_rate, auth.author, group_concat(c.category_name) as category, UNIX_TIMESTAMP(b.modification_time) as unix_ts_in_secs
FROM Book b
LEFT JOIN Book_Category bc ON b.book_id = bc.book_id
JOIN Category c ON c.category_id = bc.category_id
join (
SELECT GROUP_CONCAT(a.author_name) as author, b.book_id as book
from Book b
left join Book_Author ba on b.book_id = ba.book_id
JOIN Author a on ba.author_id = a.author_id
GROUP by b.book_id
) auth on b.book_id = auth.book
WHERE b.book_state = 'ON_SALE' and UNIX_TIMESTAMP(b.modification_time) > :sql_last_value and b.modification_time < now()
group by b.book_id
order by modification_time ascQuery문은 다음과 같이 작성하였는데, 내 경우에는 다른 테이블에서 여러 컬럼들을 참조해 와야 했기 때문에 Join을 여러번 사용하여 작성하게 되었다
사용할 데이터(elasticsearch에 저장할 데이터) 만 가져오면 되기 때문에 알아서 작성하면 되는 부분이고,
중요한 것은
UNIX_TIMESTAMP(b.modification_time) > :sql_last_value and b.modification_time < now()WHERE 절의 이 부분인데, 데이터베이스 테이블에 modification_time 이라는 DATETIME 형식의 컬럼을 하나 만들어 주어야 한다
또한, 해당 레코드가 업데이트될 때마다 modification_time을 현재 시각으로 업데이트 해주는 로직을 작성해야 한다
그래야 `UNIX_TIMESTAMP(b.modification_time)` 이라는 업데이트된 수정 시간이 `:sql_last_value` 의 기존 값 보다 커지게 되면서 변경 감지가 되어 해당 레코드를 업데이트 시켜 줄 수 있기 때문이다
UNIX_TIMESTAMP(b.modification_time) as unix_ts_in_secs추가로, 위에서 말한 modification_time을 사용하기 위해서 위와 같이 자신의 테이블에 있는 modification_time을 가져와서 별칭을 지정해 준다
이는 logstash.conf 의 input 내의 tracking_colum 속성에 사용 된다
tracking_column => "unix_ts_in_secs"
모두 설정이 완료되었다면, 저장 후 에디터를 나오면 된다
나오는 단축키는 아래와 같다
# 입력 모드 종료
ESC
# 저장 후 종료
:wq
# logstash 컨테이너 접속 해제
exit
이제 대망의 테스트 시간이다. logstash를 재시작 해보자
sudo docker restart logstash
그리고 logstash의 내부 로그를 보며... 쿼리문이 뜨기를 기도하면 끝
sudo docker logs -f logstash
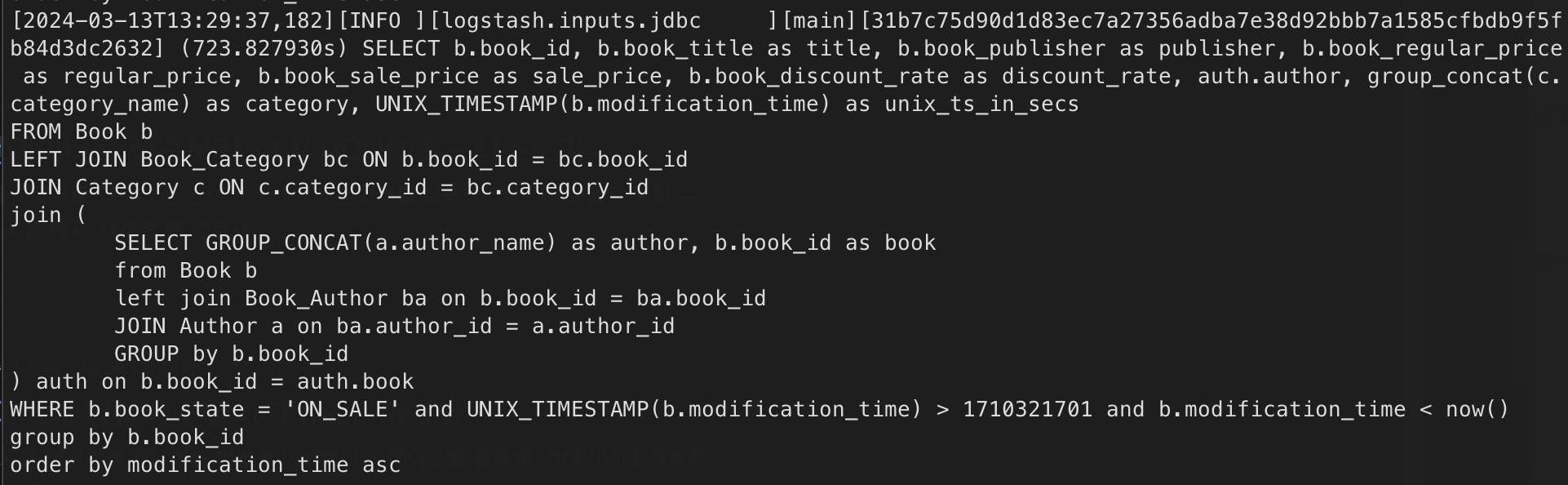
만약 위와 같은 쿼리문이 몇초 간격으로 계속 나타나고 있다면 성공이다..!
혹시라도 오류가 발생한다면 모든 컨테이너를 종료시킨 후에 재시작 해보자
sudo docker stop elasticsearch
sudo docker stop kibana
sudo docker stop logstash
sudo docker start elasticsearch
sudo docker start kibana
sudo docker start logstash
여기까지가 일단 무작정 ELK 모두 설치하고, 초기 설정을 완료하였다
물론 해야할 건 더 많다.. elasticsearch 인덱스 생성부터 analayzer 설정, filter 설정, mapping 등등...
일단 오늘은 여기까지 하고, 다음에 시간이 난다면 정리해서 "진짜" 검색을 위한... 엘라스틱서치 설정에 대해서 공부해서 올리도록 하겠다!
긴 글 읽어 주셔서 감사합니다!

댓글